اخبار, مراکز داده, مقالات تخصصی
بهینهسازی شبکه برای پردازشهای هوش مصنوعی با سوئیچهای Cisco Nexus 9000

بهمن
نقش هوش مصنوعی در بهینهسازی زیرساختهای سازمانی
هوش مصنوعی (AI) امروزه به عاملی کلیدی برای افزایش بهرهوری، بهینهسازی گردش کار و تسریع نوآوری در صنایع مختلف تبدیل شده است. این موضوع باعث شده سازمانها سرمایهگذاری بیشتری روی پردازندههای یادگیری عمیق، شتابدهندهها و واحدهای پردازش عصبی (NPU) داشته باشند. برخی شرکتها از فناوری RAG (Retrieval-Augmented Generation) برای پردازش استنتاجی استفاده میکنند و بهتدریج مقیاس خود را افزایش میدهند. همچنین، سازمانهایی که حجم بالایی از دادههای خصوصی را پردازش میکنند، ترجیح میدهند clusterهای آموزشی اختصاصی ایجاد کنند تا مدلهای سفارشیشده و دقیقتری داشته باشند.
چرا طراحی شبکه مقیاسپذیر برای clusterهای هوش مصنوعی اهمیت دارد؟
چه در حال راهاندازی یک cluster کوچک با چند صد شتابدهنده باشید و چه یک زیرساخت عظیم با هزاران شتابدهنده، داشتن یک شبکه مقیاسپذیر و بهینه امری حیاتی است. طراحی مناسب شبکه تأثیر مستقیمی بر عملکرد شتابدهندهها، زمان تکمیل پردازشها و کاهش تأخیر نهایی (Tail Latency) دارد. یکی از چالشهای اصلی، کنترل ازدحام (Congestion) بهویژه در شرایطی مانند In-Cast Scenarios است.
مدیریت ازدحام در مراکز داده با DCQCN
Quantized Congestion Notification (DCQCN) ترکیبی از دو فناوری کلیدی برای کنترل ازدحام در مراکز داده است:
🔹 Explicit Congestion Notification (ECN): برای واکنش سریع در سطح جریان دادهها
🔹 Priority Flow Control (PFC): برای کاهش تراکم و جلوگیری از از دست رفتن بستهها
سوئیچهای Cisco Nexus 9000 Series با استفاده از DCQCN، عملکرد بهینهای را در clusterهای آموزشی هوش مصنوعی ارائه میدهند.
روشهای تعادل بار در شبکههای هوش مصنوعی
روش سنتی: Equal-Cost Multi-Path (ECMP)
در روش ECMP، دادهها یک مسیر مشخص را دنبال میکنند و تا پایان پردازش در همان مسیر باقی میمانند. این رویکرد در برخی موارد میتواند باعث مصرف نامتعادل منابع شبکه و ایجاد ازدحام در مسیرهای پرترافیک شود که در نهایت، زمان پردازش مدلهای هوش مصنوعی را افزایش میدهد.
روش پیشرفته: Dynamic Load Balancing (DLB)
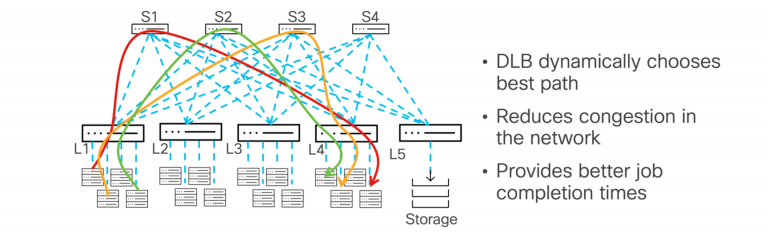
در مقابل، DLB با استفاده از تلهمتری شبکه (Network Telemetry) وضعیت ترافیک را در لحظه بررسی کرده و جریانهای داده را به مسیرهای کمتراکم منتقل میکند. این روش نهتنها از ازدحام جلوگیری میکند، بلکه عملکرد کلی شبکه را نیز بهبود میبخشد.
- Flowlet Mode: در این حالت، DLB میزان استفاده از لینکها را پایش کرده و اگر مسیر اولیه شلوغ شود، بستههای بعدی را از مسیرهای دیگر عبور میدهد.
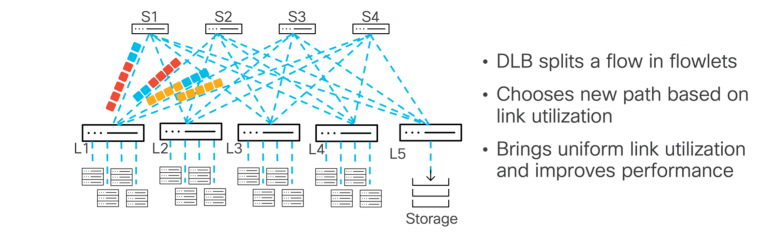
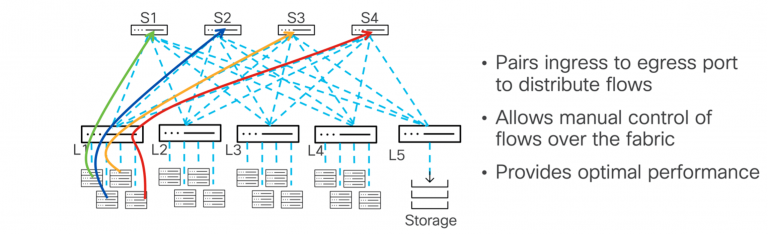
- Static Pinning Mode: این قابلیت امکان جفتسازی دستی ورودی و خروجی پورتها را از طریق CLI یا API فراهم میکند و کنترل دقیقتری روی توزیع بار ایجاد مینماید.
- Per-Packet Load Balancing: این روش بستهها را بهصورت تصادفی بین مسیرهای مختلف توزیع میکند تا حداکثر استفاده از پهنای باند را داشته باشد. البته این رویکرد ممکن است باعث نامرتب رسیدن بستهها (Out-of-Order Packets) شود که در مقصد نیاز به بازترتیب (Reordering) خواهند داشت.
آمادگی برای آینده: Ultra Ethernet
سوئیچهای Cisco Nexus 9000 از Ultra Ethernet (UEC) پشتیبانی میکنند که بهعنوان یک پروتکل مقیاسپذیر و منعطف، بدون نیاز به Handshake عمل میکند. این فناوری جدید، تأخیر شبکه را کاهش داده، هزینههای مربوط به NIC را کم کرده و با قابلیتهایی مانند Packet Trimming، مدیریت هوشمند ازدحام را بهبود میبخشد.
چرا Cisco Nexus 9000 برای پردازشهای هوش مصنوعی ایدهآل است؟
- پشتیبانی از Dynamic Load Balancing (DLB) برای افزایش کارایی شبکه
مجهز به DCQCN برای مدیریت هوشمند ترافیک - سازگاری با Ultra Ethernet (UEC) و Ultra Ethernet Transport (UET) برای پردازشهای AI و HPC
- کنترل دقیق توزیع بار با قابلیت Static Pinning
- پشتیبانی از Per-Packet Load Balancing برای استفاده بهینه از پهنای باند
آینده شبکههای هوش مصنوعی را با Cisco Nexus 9000 بسازید
با سوئیچهای Cisco Nexus 9000 Series، یک شبکه سریع، مقیاسپذیر و مطمئن برای پردازشهای هوش مصنوعی خود ایجاد کنید و از فناوریهای پیشرفته Ultra Ethernet بهرهمند شوید. همین امروز Dynamic Load Balancing را فعال کنید و در آینده، با استانداردهای UEC، شبکه خود را ارتقا دهید.